Coding and Transmission
Image coding, video coding, 3D data coding, encoded data transmission.
Image Understanding
Semantic segmentation, continual learning, federated learning, multi-modal learning, hand gesture recognition.
Learned compression
More recently, compression strategies have been adopting deep learning architecture to achieve high compression ratios while granting a pleasant and satisfying visual quality. In our investigation we focus on feature optimization for autoencoder-based codecs, generative coding strategies based on diffusion models, coding schemes based on neural implicit representation (NIR).
Point cloud compression

Point cloud are among the most versatile and widely-adopted 3D modelling formats as they can be generated using different algorithms or devices, e.g., LiDAR, ToF cameras, SfM algorithms, laser scanners, and more. The compression and transmission of static and dynamic point clouds is a challenging issue that is worth of being investigated. In our research, we designed several strategies involving classical coding techniques as well as learned compression strategies.
Low-latency Video Transmission

Low latency is a key requisite for many video transmission services. Traditional approaches focus on reducing the latency coming from transmission and coding. We propose a novel approach where latency is controlled by temporal extrapolation of the next video frames. The idea is promising since it has the potential of an arbitrary latency reduction. However several challenged must be faced to make it suitable for real-life applications: the quality of the extrapolated images; the trade-off between extrapolation complexity and latency reduction; the integration into a full-scale streaming system. We explore these topics in our recent publications and in upcoming projects.
Immersive Video Coding and Transmission
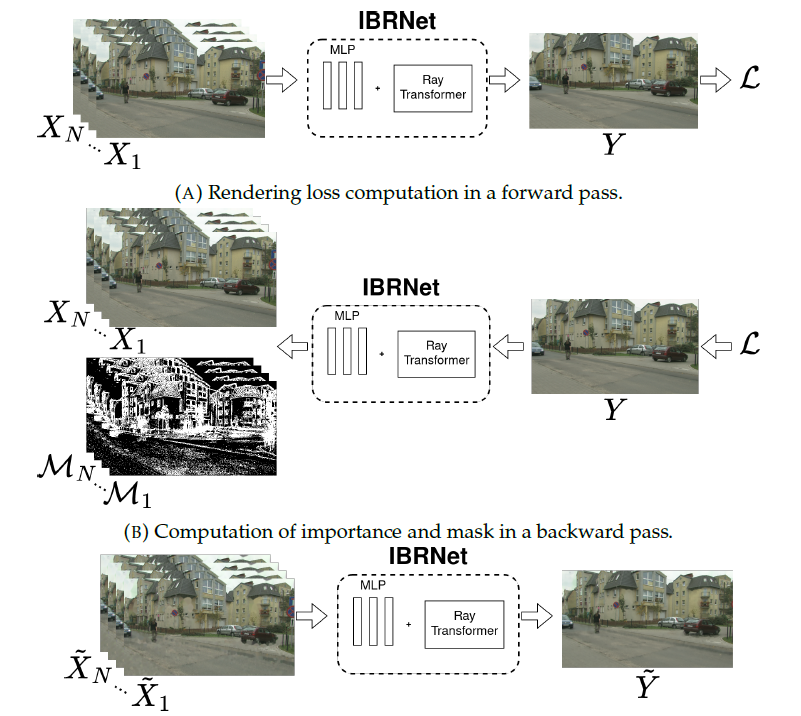
In the Multiview Video plus Depth (MVD) format, geometry information is provided through depth maps associated with each camera. Compared to traditional 2D video, MVD requires a substantial amount of data to provide viewers with an accurate perception of scene depth. Due to the increasing demand for immersive video consumption, efficient compression and transmission of immersive media have become crucial tasks for standardization bodies.
We study the problem of efficient data reduction (pixel pruning) and associated viewpoint synthesis.
Linear Video Coding
Linear Video Coding LVC is an emerging paradigm for video transmission, in which all the non-linear processing steps are discarded. As a consequence, the full coding and transmission chain is linear, resulting in the fact that, the better the channel between the video source and the destination, the better the quality experienced by the latter.
In order to make LVC competitive with state-of-the-art video compression and transmission systems, several challenges must be addressed. To this end, we introduce tools concerning dimensionality reduction, power allocation, and sophisticated noise models.
Continual Learning
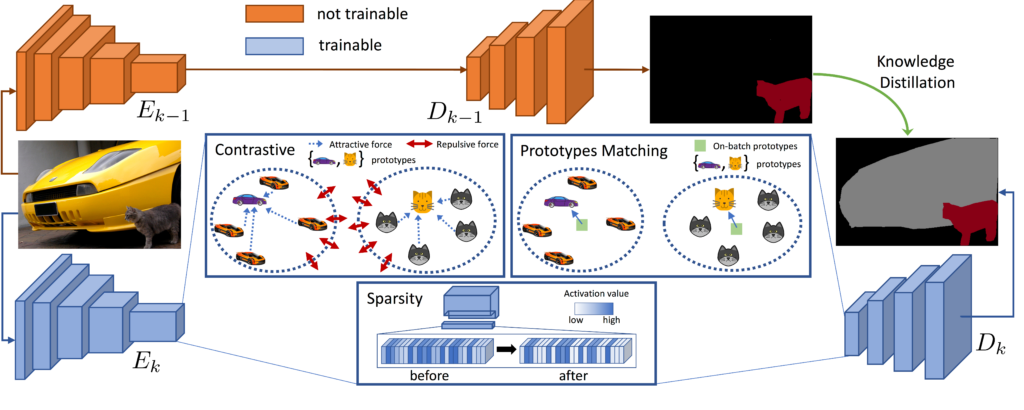
Continual learning refers to the ability of a machine learning model to continuously acquire and retain knowledge from new data while retaining previously learned information. In the MEDIA Lab we explored continual learning for semantic segmentation, focusing on the autonomous driving context.
Domain Adaptation

Domain adaptation focuses on transferring knowledge learned from one domain to another related domain. It deals with the problem of distribution shift, where the training and test data come from different distributions. In the MEDIA Lab we explored domain adaptation for semantic segmentation in different settings.
Federated Learning
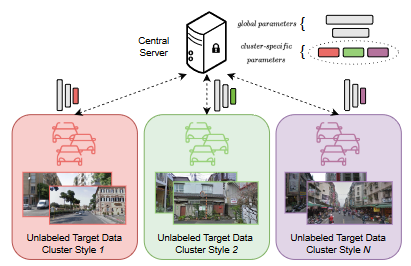
Federated learning allows multiple devices or entities to collaboratively train a shared model while keeping their local data private. It enables devices to perform local model updates using their local data, and only the model updates are sent to the central server for aggregation. In the MEDIA Lab we explored federated learning in computer vision problems like image classification and semantic segmentation.
Hand Gesture Recognition
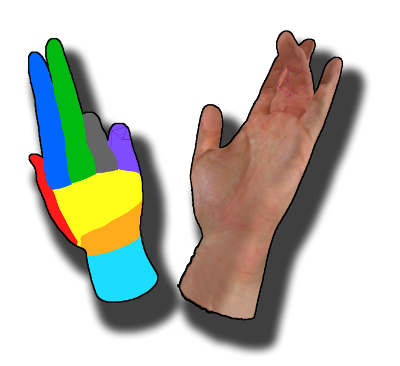
Hand gesture recognition is a computer vision task that involves detecting and interpreting hand movements and poses to understand the intended meaning or command conveyed by the gestures. In the MEDIA Lab we developed hand gesture recognition approaches exploiting image and depth data.
Multi-Modal Learning

Multimodal learning is an area of machine learning that deals with the integration and analysis of information from multiple modalities, such as text, images, audio, and video. By combining data from different modalities, multimodal learning aims to improve the performance and understanding of complex tasks that cannot be effectively addressed by using a single modality alone.

Quality Assessment
Quality assessment for 2D, 3D, multiview and immersive media.

3D Modeling, Sensing and Understanding
3D reconstruction, stereo vision, ToF sensing, augmented reality, explicit representation compression.
Neural Rendering and 3D Reconstruction

Neural Rendering, Gaussian Splatting and NeRF-based novel view synthesis, 3D reconstruction from RGB images, Multimodal Neural Radiance Fields.
LiDAR Point cloud processing

During the last years, LiDAR point clouds are among the most challenging media to process due to sparsity, distortion, time drifts and storage space/transmission rate. We are investigating efficient learned algorithms for their processing and understanding.
eXtended/Augmented/Virtual/Mixed Reality
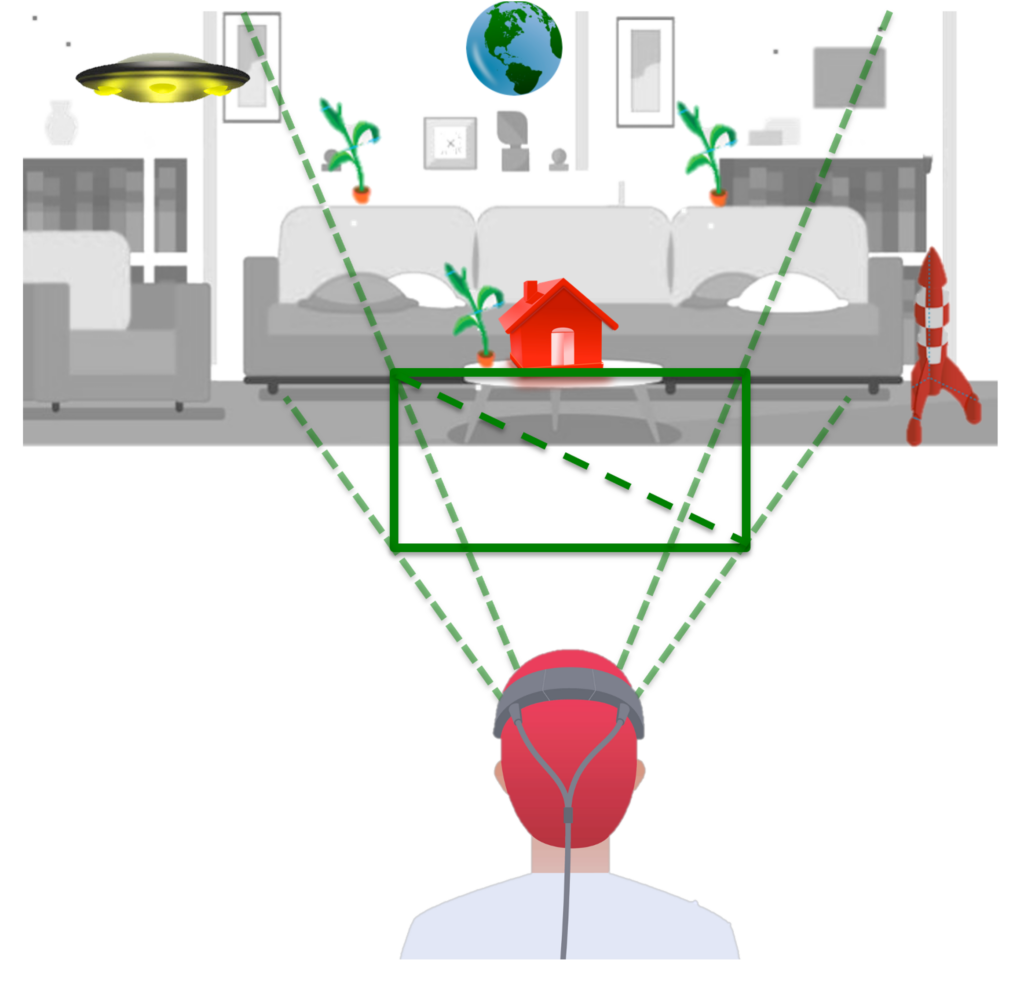
Extended reality (XR) is a term to refer to augmented reality (AR), virtual reality (VR), mixed reality (MR), letting “X” be an arbitrary variable that can interpolate between these various realities or eXtrapolate (eXtend) beyond them. The technology is intended to combine or mirror the physical world with a “digital twin world” able to interact with it.
Time-Of-Flight sensors

Denoising and Multi-Path Interference (MPI) removal techniques for Time-of-Flight (ToF) sensors, stereo and ToF data fusion.
Classification and Retrieval of 3D Objects

Classification of 3D objects with deep learning, 3D objects’ retrieval

Computational Image and Signal Processing
Computational imaging, hyper-spectral imaging, monocular depth estimation, image restoration and enhancement, generative algorithms.

Forensics, biometrics and security
Forensics AI; multimedia forensics and biometrics; adversarial machine learning; network anomaly detection.
Spectral Imaging

Hyper-spectral image reconstruction from RGB data and from measurements obtained by a CTIS snapshot spectrometer.
Monocular Depth Estimation with Optimized Optics

Depth estimation using aperture-engineered imaging devices.
Multimedia forensics

Analysis and identification of image, video, and audio content, with a focus on detecting synthetic media generated by deep learning techniques (e.g., GANs and deepfakes), including continual learning approaches for robust detection.
Authentication, privacy and fairness issues
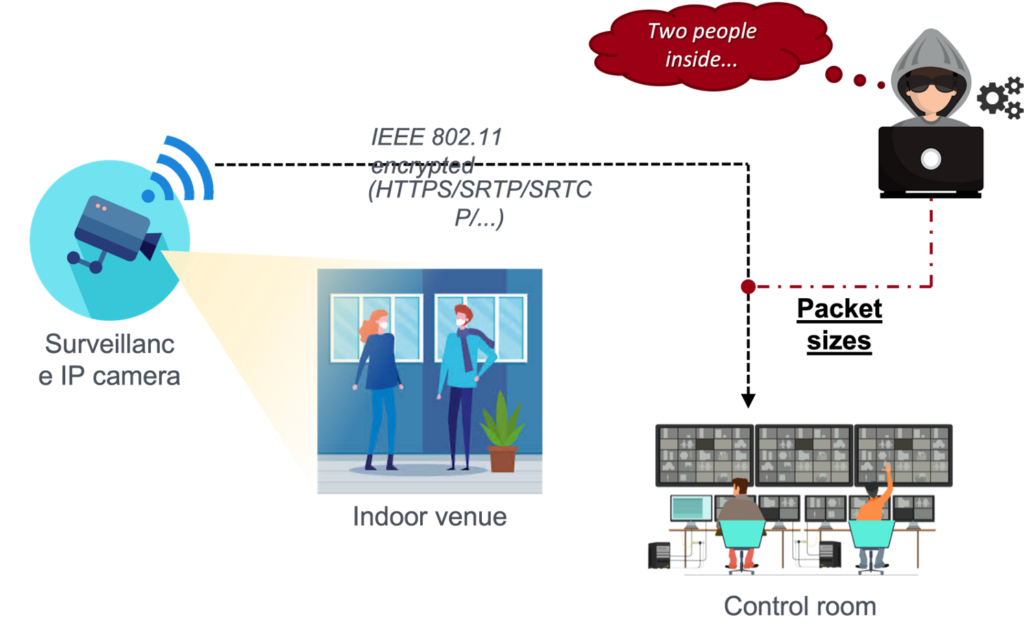
Study of biometric systems, information leakage, and inference attacks on multimedia and generative models, including multimodal approaches for forensic data analysis and augmentation, with attention to privacy, security, and fairness implications.
Network Anomaly Detection
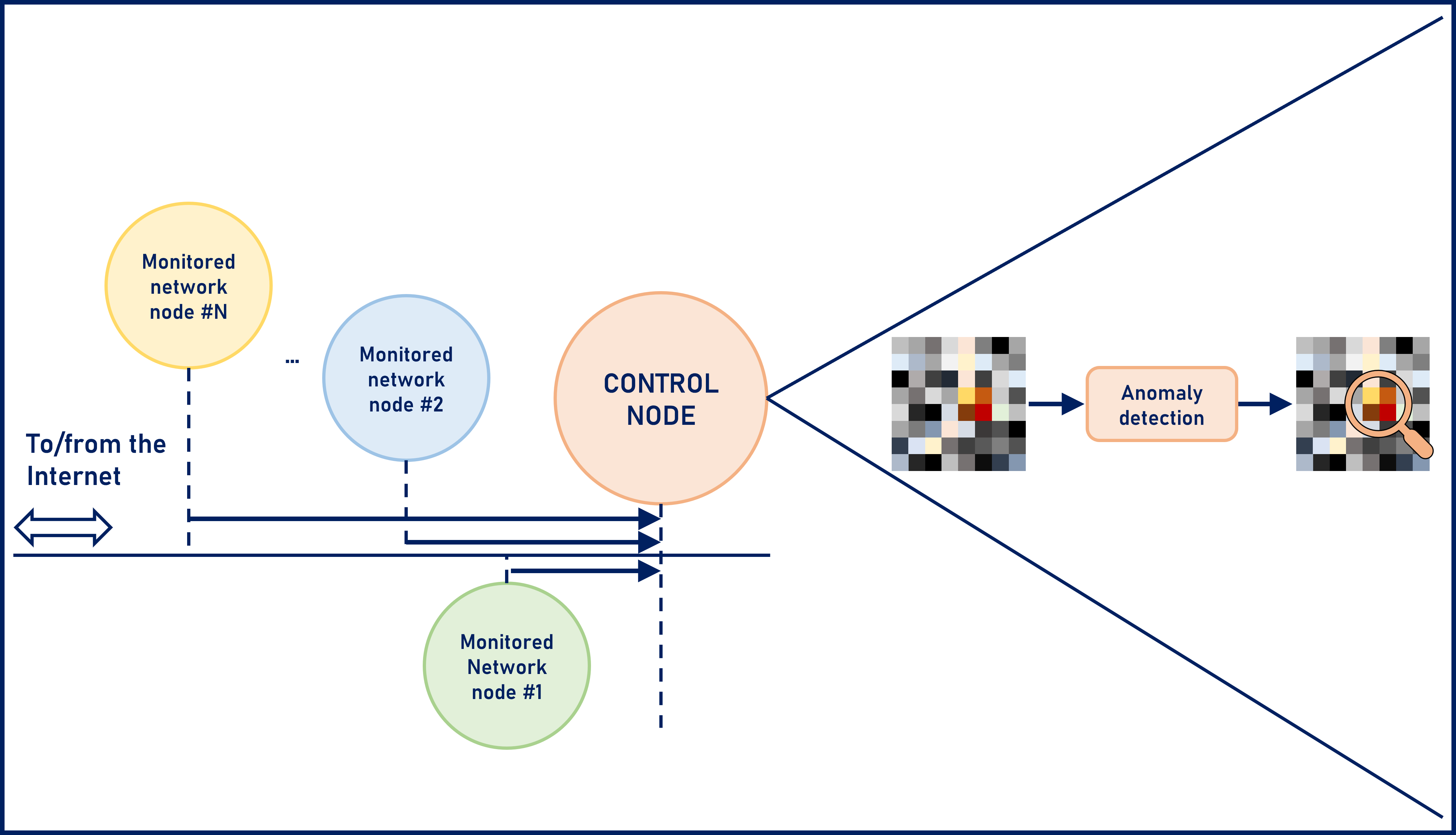
Detect anomalies in a monitored network based on a 2D representation of traffic data