A color image not always contains enough information to capture the semantic content of a scene. Multi-modal learning techniques jointly exploit the color information and other representations (e.g., depth maps capturing the geometry of the scene) in order to improve the semantic understanding of complex scenes. Have a look here for a review of recent work in this field.

Key research topics include:
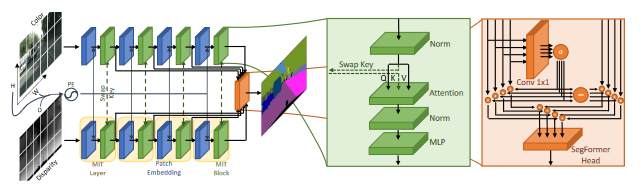
- We proposed a novel multi-modal semantic segmentation scheme based on vision transformers where we jointly exploited multimodal positional embeddings and a cross-input attention scheme
- We introduced a multimodal dataset (SELMA) for autonomous driving containing multiple color and depth cameras in variable daytime and weather conditions
- We jointly exploited color and surface information clues to improve clustering-based segmentation methods
Selected publications:
Continual Road-Scene Semantic Segmentation via Feature-Aligned Symmetric Multi-Modal Network Proceedings Article
In: IEEE International Conference on Image Processing (ICIP), 2024.
Source-Free Domain Adaptation for RGB-D Semantic Segmentation with Vision Transformers Proceedings Article
In: Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, pp. 615–624, 2024.
SELMA: SEmantic Large-Scale Multimodal Acquisitions in Variable Weather, Daytime and Viewpoints Journal Article
In: IEEE Transactions on Intelligent Transportation Systems, pp. 1–13, 2023.
DepthFormer: Multimodal Positional Encodings and Cross-Input Attention for Transformer-Based Segmentation Networks Proceedings Article
In: ICASSP 2023-2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2023.
Multimodal Semantic Segmentation in Autonomous Driving: A Review of Current Approaches and Future Perspectives Journal Article
In: Technologies, vol. 10, no. 4, pp. 90, 2022.