The latest 3D acquisition mechanisms have enabled the modelling of real 3D scenes using unordered sets of 3D points, which can be accompanied by different attributes, e.g., colour components, normals, semantic labels, and sensing-related measurements.
These sets of points are called Point Clouds and they are typically composed of hundreds of points; that is why they are always storage-consuming and always require a long time to be processed.
Among the most popular acquisition systems, we can find LiDARs. These devices use the light from a laser, producing a sparse prediction of the environment in the form of point clouds. LiDAR point clouds are common data used in various deep learning tasks such as visual scene understanding, compression and completion.
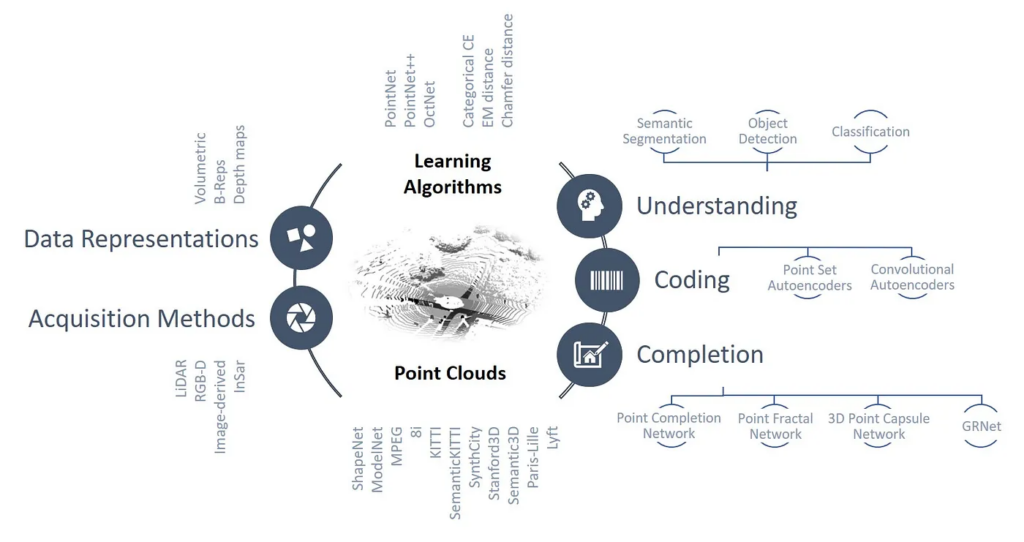
Read more here: https://medium.com/@elenacamuffo97/recent-advancements-in-learning-algorithms-for-point-clouds-an-updated-overview-35eabf511183
Key research topics include:
- Point cloud semantic segmentation
- Point cloud semantic compression
Recent publications:
Schiavo, Chiara; Camuffo, Elena; Milani, Simone
SAGE: Semantic-Driven Adaptive Gaussian Splatting in Extended Reality Conference
EUSIPCO, 2025.
@conference{nokey,
title = {SAGE: Semantic-Driven Adaptive Gaussian Splatting in Extended Reality},
author = {Chiara Schiavo and Elena Camuffo and Simone Milani},
url = {https://www.arxiv.org/pdf/2503.16747},
year = {2025},
date = {2025-01-01},
urldate = {2025-01-01},
booktitle = {EUSIPCO},
abstract = {3D Gaussian Splatting (3DGS) has significantly improved the efficiency and realism of three-dimensional scene visualization in several applications, ranging from robotics to eXtended Reality (XR). This work presents SAGE (Semantic- Driven Adaptive Gaussian Splatting in Extended Reality), a novel framework designed to enhance the user experience by dynamically adapting the Level of Detail (LOD) of different 3DGS objects identified via a semantic segmentation. Experimental results demonstrate how SAGE effectively reduces memory and computational overhead while keeping a desired target visual quality, thus providing a powerful optimization for interactive XR applications.},
keywords = {},
pubstate = {published},
tppubtype = {conference}
}
Barbato, Francesco; Camuffo, Elena; Milani, Simone; Zanuttigh, Pietro
Continual Road-Scene Semantic Segmentation via Feature-Aligned Symmetric Multi-Modal Network Proceedings Article
In: IEEE International Conference on Image Processing (ICIP), 2024.
@inproceedings{barbato2023continualb,
title = {Continual Road-Scene Semantic Segmentation via Feature-Aligned Symmetric Multi-Modal Network},
author = {Francesco Barbato and Elena Camuffo and Simone Milani and Pietro Zanuttigh},
url = {https://arxiv.org/pdf/2308.04702.pdf},
year = {2024},
date = {2024-06-25},
urldate = {2024-06-25},
booktitle = {IEEE International Conference on Image Processing (ICIP)},
journal = {arXiv preprint arXiv:2308.04702},
abstract = {State-of-the-art multimodal semantic segmentation approaches combining LiDAR and color data are usually designed on top of asymmetric information-sharing schemes and assume that both modalities are always available. Regrettably, this strong assumption may not hold in real-world scenarios, where sensors are prone to failure or can face adverse conditions (night-time, rain, fog, etc.) that make the acquired information unreliable. Moreover, these architectures tend to fail in continual learning scenarios. In this work, we re-frame the task of multimodal semantic segmentation by enforcing a tightly-coupled feature representation and a symmetric information-sharing scheme, which allows our approach to work even when one of the input modalities is missing. This makes our model reliable even in safetycritical settings, as is the case of autonomous driving. We evaluate our approach on the SemanticKITTI dataset, comparing it with our closest competitor. We also introduce an ad-hoc continual learning scheme and show results in a class-incremental continual learning scenario that prove the effectiveness of the approach also in this setting.},
keywords = {},
pubstate = {published},
tppubtype = {inproceedings}
}
Devid, Campagnolo*; Elena, Camuffo*; Umberto, Michieli; Paolo, Borin; Simone, Milani; Andrea, Giordano
Fully Automated Scan-to-BIM via Point Cloud Instance Segmentation Proceedings Article
In: International Conference on Image Processing (ICIP), IEEE 2023.
@inproceedings{Camuffo2023c,
title = {Fully Automated Scan-to-BIM via Point Cloud Instance Segmentation},
author = {Campagnolo* Devid and Camuffo* Elena and Michieli Umberto and Borin Paolo and Milani Simone and Giordano Andrea
},
url = {https://ieeexplore.ieee.org/stamp/stamp.jsp?tp=&arnumber=10222064},
year = {2023},
date = {2023-09-13},
urldate = {2023-09-13},
booktitle = {International Conference on Image Processing (ICIP)},
organization = {IEEE},
abstract = {Digital reconstruction through Building Information Models (BIM) is a valuable methodology for documenting and analyzing existing buildings. Its pipeline starts with geometric acquisition. (e.g., via photogrammetry or laser scanning) for accurate point cloud collection. However, the acquired data are noisy and unstructured, and the creation of a semanticallymeaningful BIM representation requires a huge computational effort, as well as expensive and time-consuming human annotations. In this paper, we propose a fully automated scan-to-BIM pipeline. The approach relies on: (i) our dataset (HePIC), acquired from two large buildings and annotated at a point-wise semantic level based on existent BIM models; (ii) a novel ad hoc deep network (BIM-Net++) for semantic segmentation, whose output is then processed to extract instance information necessary to recreate BIM objects; (iii) novel model pretraining and class re-weighting to eliminate the need for a large amount of labeled data and human intervention.},
keywords = {},
pubstate = {published},
tppubtype = {inproceedings}
}
Mari, Daniele; Camuffo, Elena; Milani, Simone
CACTUS: Content-Aware Compression and Transmission Using Semantics for Automotive LiDAR Data Journal Article
In: Sensors, vol. 23, iss. 12, 2023.
@article{Mari,
title = {CACTUS: Content-Aware Compression and Transmission Using Semantics for Automotive LiDAR Data},
author = {Daniele Mari and Elena Camuffo and Simone Milani},
editor = {MDPI},
url = {https://www.mdpi.com/1424-8220/23/12/5611},
doi = {10.3390/s23125611},
year = {2023},
date = {2023-06-15},
urldate = {2023-06-15},
journal = {Sensors},
volume = {23},
issue = {12},
abstract = {Many recent cloud or edge computing strategies for automotive applications require transmitting huge amounts of Light Detection and Ranging (LiDAR) data from terminals to centralized processing units. As a matter of fact, the development of effective Point Cloud (PC) compression strategies that preserve semantic information, which is critical for scene understanding, proves to be crucial. Segmentation and compression have always been treated as two independent tasks; however, since not all the semantic classes are equally important for the end task, this information can be used to guide data transmission. In this paper, we propose Content-Aware Compression and Transmission Using Semantics (CACTUS), which is a coding framework that exploits semantic information to optimize the data transmission, partitioning the original point set into separate data streams. Experimental results show that differently from traditional strategies, the independent coding of semantically consistent point sets preserves class information. Additionally, whenever semantic information needs to be transmitted to the receiver, using the CACTUS strategy leads to gains in terms of compression efficiency, and more in general, it improves the speed and flexibility of the baseline codec used to compress the data.},
keywords = {},
pubstate = {published},
tppubtype = {article}
}
Camuffo, Elena; Milani, Simone
Continual Learning for LiDAR Semantic Segmentation: Class-Incremental and Coarse-to-Fine strategies on Sparse Data Proceedings Article
In: International Conference of Computer Vision and Pattern Recognition Workshops, 2023.
@inproceedings{Camuffo2023b,
title = {Continual Learning for LiDAR Semantic Segmentation: Class-Incremental and Coarse-to-Fine strategies on Sparse Data},
author = {Elena Camuffo and Simone Milani},
url = {https://arxiv.org/abs/2304.03980},
doi = {https://doi.org/10.48550/arXiv.2304.03980},
year = {2023},
date = {2023-04-10},
urldate = {2023-04-10},
booktitle = {International Conference of Computer Vision and Pattern Recognition Workshops},
abstract = {During the last few years, continual learning (CL) strategies for image classification and segmentation have been widely investigated designing innovative solutions to tackle catastrophic forgetting, like knowledge distillation and self-inpainting. However, the application of continual learning paradigms to point clouds is still unexplored and investigation is required, especially using architectures that capture the sparsity and uneven distribution of LiDAR data. The current paper analyzes the problem of class incremental learning applied to point cloud semantic segmentation, comparing approaches and state-of-the-art architectures. To the best of our knowledge, this is the first example of class-incremental continual learning for LiDAR point cloud semantic segmentation. Different CL strategies were adapted to LiDAR point clouds and tested, tackling both classic fine-tuning scenarios and the Coarse-to-Fine learning paradigm. The framework has been evaluated through two different architectures on SemanticKITTI, obtaining results in line with state-of-the-art CL strategies and standard offline learning.},
keywords = {},
pubstate = {published},
tppubtype = {inproceedings}
}
Camuffo, Elena; Michieli, Umberto; Milani, Simone
Learning from Mistakes: Self-Regularizing Hierarchical Representations in Point Cloud Semantic Segmentation Journal Article
In: IEEE Transactions on Multimedia, pp. 1-11, 2023.
@article{Camuffo2023,
title = {Learning from Mistakes: Self-Regularizing Hierarchical Representations in Point Cloud Semantic Segmentation},
author = {Elena Camuffo and Umberto Michieli and Simone Milani},
url = {https://ieeexplore.ieee.org/stamp/stamp.jsp?arnumber=10368362},
doi = {10.1109/TMM.2023.3345152},
year = {2023},
date = {2023-01-01},
urldate = {2023-01-01},
journal = {IEEE Transactions on Multimedia},
pages = {1-11},
abstract = {Recent advances in autonomous robotic technologies have highlighted the growing need for precise environmental analysis. LiDAR semantic segmentation has gained attention to accomplish fine-grained scene understanding by acting directly on raw content provided by sensors. Recent solutions showed how different learning techniques can be used to improve the performance of the model, without any architectural or dataset change. Following this trend, we present a coarse-to-fine setup that LEArns from classification mistaKes (LEAK) derived from a standard model. First, classes are clustered into macro groups according to mutual prediction errors; then, the learning process is regularized by: (1) aligning class-conditional prototypical feature representation for both fine and coarse classes, (2) weighting instances with a per-class fairness index. Our LEAK approach is very general and can be seamlessly applied on top of any segmentation architecture; indeed, experimental results showed that it enables state-of-the-art performances on different architectures, datasets and tasks, while ensuring more balanced class-wise results and faster convergence.},
keywords = {},
pubstate = {published},
tppubtype = {article}
}
Camuffo, Elena; Mari, Daniele; Milani, Simone
Recent advancements in learning algorithms for point clouds: An updated overview Journal Article
In: Sensors, vol. 22, no. 4, pp. 1357, 2022.
@article{Camuffo2022,
title = {Recent advancements in learning algorithms for point clouds: An updated overview},
author = {Elena Camuffo and Daniele Mari and Simone Milani},
url = {https://www.mdpi.com/1424-8220/22/4/1357},
doi = {https://doi.org/10.3390/s22041357},
year = {2022},
date = {2022-01-01},
urldate = {2022-01-01},
journal = {Sensors},
volume = {22},
number = {4},
pages = {1357},
publisher = {MDPI},
abstract = {Recent advancements in self-driving cars, robotics, and remote sensing have widened the range of applications for 3D Point Cloud (PC) data. This data format poses several new issues concerning noise levels, sparsity, and required storage space; as a result, many recent works address PC problems using Deep Learning (DL) solutions thanks to their capability to automatically extract features and achieve high performances. Such evolution has also changed the structure of processing chains and posed new problems to both academic and industrial researchers. The aim of this paper is to provide a comprehensive overview of the latest state-of-the-art DL approaches for the most crucial PC processing operations, i.e., semantic scene understanding, compression, and completion. With respect to the existing reviews, the work proposes a new taxonomical classification of the approaches, taking into account the characteristics of the acquisition set up, the peculiarities of the acquired PC data, the presence of side information (depending on the adopted dataset), the data formatting, and the characteristics of the DL architectures. This organization allows one to better comprehend some final performance comparisons on common test sets and cast a light on the future research trends.},
keywords = {},
pubstate = {published},
tppubtype = {article}
}
Milani, Simone
Adae: Adversarial distributed source autoencoder for point cloud compression Proceedings Article
In: 2021 IEEE International Conference on Image Processing (ICIP), pp. 3078–3082, IEEE 2021.
@inproceedings{Milani2021b,
title = {Adae: Adversarial distributed source autoencoder for point cloud compression},
author = {Simone Milani},
year = {2021},
date = {2021-01-01},
urldate = {2021-01-01},
booktitle = {2021 IEEE International Conference on Image Processing (ICIP)},
pages = {3078--3082},
organization = {IEEE},
keywords = {},
pubstate = {published},
tppubtype = {inproceedings}
}
Agresti, Gianluca; Milani, Simone
Material identification using RF sensors and convolutional neural networks Proceedings Article
In: ICASSP 2019-2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pp. 3662–3666, IEEE 2019.
@inproceedings{Agresti2019b,
title = {Material identification using RF sensors and convolutional neural networks},
author = {Gianluca Agresti and Simone Milani},
year = {2019},
date = {2019-01-01},
urldate = {2019-01-01},
booktitle = {ICASSP 2019-2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP)},
pages = {3662--3666},
organization = {IEEE},
keywords = {},
pubstate = {published},
tppubtype = {inproceedings}
}
Lecci, Mattia; Milani, Simone
3D reconstruction from web harvested images using a forensic quality metric Proceedings Article
In: 2017 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pp. 1997–2001, IEEE 2017.
@inproceedings{Lecci2017,
title = {3D reconstruction from web harvested images using a forensic quality metric},
author = {Mattia Lecci and Simone Milani},
year = {2017},
date = {2017-01-01},
urldate = {2017-01-01},
booktitle = {2017 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP)},
pages = {1997--2001},
organization = {IEEE},
keywords = {},
pubstate = {published},
tppubtype = {inproceedings}
}